
Privacy isn’t absent from blockchains today, but its reach and use cases are still limited. Even as privacy enhancing technologies (PETs) like MPC, FHE and TEEs have slowly grown from academic theory into practical infancy, privacy has yet to make its mark on many of the onchain products that most of us actually use. But thanks to recent developments and synergies across PETs, we are finally seeing private shared state emerge for everyday blockchain users, enabling practically usable privacy.
This article builds off of the previous Privacy 1.0: PETs and the Promise of Private Shared State. While I recommend reading that before continuing, here’s a quick recap:
In Part I, we explored how Privacy 1.0 tools like mixers, dark pools, and isolated privacy protocols of old prioritized transactional secrecy at the expense of composability and user experience. These early solutions created walled gardens where privacy came at the cost of shared state: users could either keep data private or make it interoperable, but not both. This fundamental limitation stifled innovation, mirroring crypto’s pre-DeFi era where fragmented infrastructure prevented explosive use case growth. Privacy 2.0 emerged as a solution, proposing private shared state through PETs—cryptographic primitives that could collectively enable composable privacy akin to HTTPS’s standardization of web2 security. While promising, these technologies faced critical growing pains: TEEs grappled with hardware vulnerabilities, MPC with coordination overhead, and FHE with impractical computational demands, leaving Privacy 2.0 more theoretical than realized.
We also explored how Privacy 2.0 requires a standard of private shared state as well as privacy by default in order to reach a wide audience. Drawing from these attributes, we explored the potential for Privacy 2.0 to unlock new use cases in crypto, and touched on the theoretical history of PETs and why they didn’t immediately enable these unlocks for our space. The main technologies we’ve been focusing on are:
In Part II, we’ll now look at the evolution of these PETs to analyze how their often hidden implementations show their potential. Thanks to recent advancements, today’s TEEs are securing block builders and onchain agents, MPC is enabling institutional-grade data and asset management, along with private computation, and FHE libraries are powering confidential smart contracts. Crucially, we’ll examine how developers are combining these technologies in hybrid architectures (TEE+MPC consensus layers, FHE+ZK coprocessors) to mitigate individual weaknesses while creating novel privacy-preserving primitives. From compliant institutional DeFi to user-owned AI data markets, ecosystems built around PETs are finally laying the groundwork for a revolution around private shared state, where sensitive data can be computed upon in a composable manner without breaking privacy. However, this future is contingent on us navigating the new technical and regulatory complexities these advancements introduce.
The success of this revolution currently hinges on each PET’s unique set of sharp advantages in certain attributes, which we will refer to as “spikes”. Each technology currently delivers specific spikes (TEEs’ speed, MPC’s collusion resistance, FHE’s expressivity) at the cost of structural compromises that demand hybrid architectures and novel threat models. Given this, much of today’s progress has pushed us towards making PETs less spiky, so that they end up looking and feeling more like each other in practice. Developers already leverage hybrid stacks using multiple PETs to create more secure, user-friendly systems.

Following the learnings around the initial, memory-bound generation of SGX and how it was used beyond media DRM, Intel opted for a more specialized distribution model for its second generation, known as Scalable SGX. Much like the first generation of SGX, Scalable SGX wasn’t designed for crypto—it was designed to sandbox app A from B running on the same hosts in the same data centers. The key difference from SGX to Scalable SGX is that the former lives on consumer devices, while the latter exclusively lives on server-grade Intel Xeon chips inside dedicated data centers. Because of this, TEEs are often used by clients to verifiably execute code running in data centers across the world.
One might expect the hyperscale compute platforms like AWS, Azure, and Google Cloud to have verticalized confidential compute with proofs of integrity, but TEEs on these web2 platforms are sometimes delegated to generic data centers who focus on geographic distribution at the cost of verifiability. This creates a sense of security through obscurity, as you’re trusting the physical security of the data center and the chip’s manufacturing process as opposed to verifying the code inside a TEE directly. Data centers somewhat reconcile this via a standardized set of norms called Data Center Attestation Primitives (DCAP) which provide attestations that help verify that the code running remotely in a TEE is unaltered—given that the TEE itself isn’t compromised. These remote attestations have crucially driven TEE distribution through narrative trends like IoT and AI, and ultimately line up well with blockchain trust assumptions.
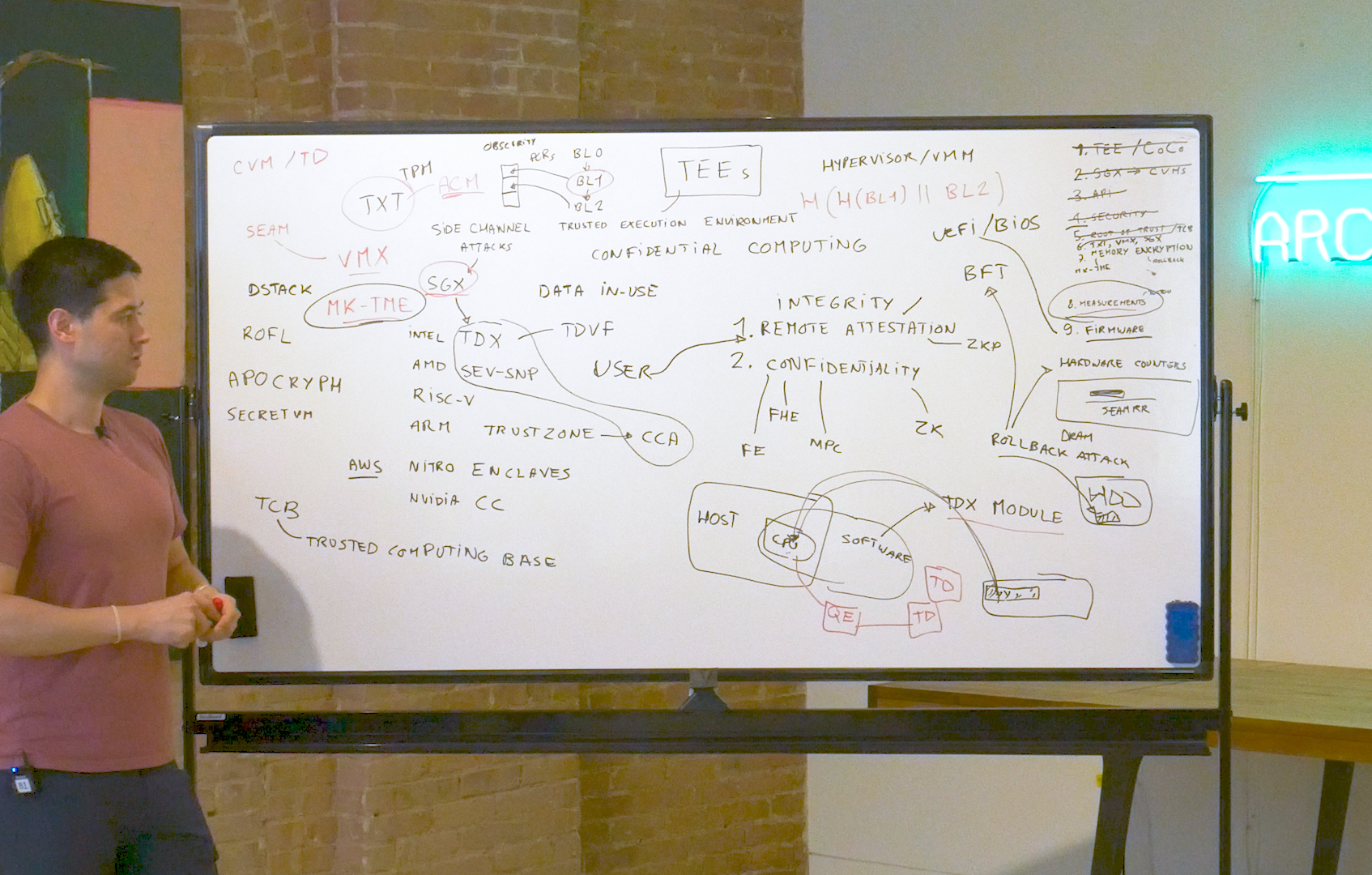
Our good friend David Wong (see above) and some other extremely smart researchers spent a few hours in our office digging into all things TEE at full depth, but here’s a reasonably detailed high level overview of TEE architecture.
Going from the initial wave of server-based TEEs, which used designated regions of hardware like Scalable SGX, VM-based tees emerged, leveraging secure firmwares with access to elastic amounts of memory and storage. Some examples of these include Intel TDX (Trust Domain Extensions) as well as AMD’s SEV-SNP.
As part of these VM-based solutions, more closed-source trust models for secure elements have become more prevalent today, with bespoke server-only designs like Amazon’s in-house Nitro chips. These are designed and implemented with the inherent trust assumption of physical security and security via the inaccessible and proprietary design.
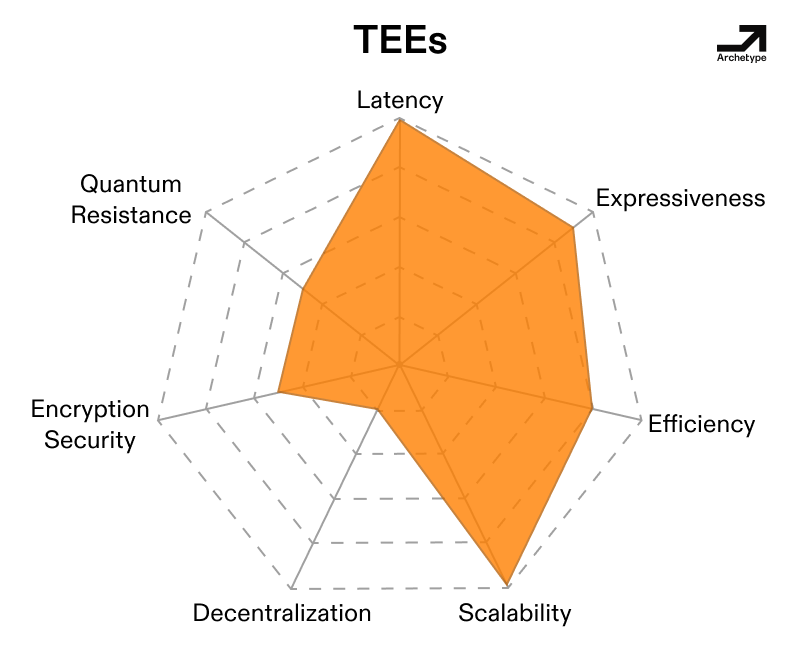
There’s a reason “stick it in a TEE” is a common refrain in research—it’s easy.
The most obvious reason for this is that TEEs simply have great distribution coupled with a good physical security model. By physical security, I mean that these TEEs are on server-grade CPUs and inference-scale GPUs, living under the same hypervisors and in the same server racks as web2 companies’ cloud infrastructure. Due to the immense value stored in those web2 assets, immense resources already go into securing these locations and racks (i.e. several Guys and Gals With Glocks). In other words, these data centers are the digital equivalents of Fort Knox. This absolutely isn’t a coincidence, as many web2 companies use these data centers and TEEs as part of their security stack for assets like passwords and credit card information.
This is important because, as we noted in Part I, the value for malicious actors to exploit a TEE must be lower than the cost to perform an exploit. Physical security raises the danger and cost of an exploit, and other valuable assets being in close proximity to TEEs adds an opportunity cost to attacking a TEE over a data center rack that a fintech company might use to store passwords and user information. Simply put, TEEs stored in data centers are expensive to access physically and are surrounded by more easily accessible stores of value.
Communities are rallying around these benefits—TEE discourse has been wildly active in the past few months, with numerous threads on developer experience in the Flashbots forums, discussions on open source and trustless design across various Telegram groups and Discord servers, and open source TEE security being a core part of Poetic Technologies’ Stakeholder meetings.
TEEs can also be put into secure communication with each other using standard and performant networking rails like TLS combined with TEE-specific characteristics like Remote Attestation. The combination of TEEs living inside web2 cloud infrastructure while also being able to dynamically generate attestations in place of static certificates creates a natural distribution of verifiable infrastructure. All of this makes for web2-like speeds with web3-like verifiability on builds of software and collaborative computation.
Still, there are reasons why the end state of things isn’t to blindly trust manufacturers and operators of closed source TEEs.
Though innovations like Google’s Skywater PDK hint at more auditable and open-source hardware, open source TEEs are currently stuck on twenty year old chip building blocks (with each gate on the chip being ~130 nm). While closed source TEEs are built on more modern chip processes, their proprietary designs have been shown many times to be exploitable by physical side-channel attacks—from power consumption patterns to cache timing—which are threats to sensitive data as it is being processed and computed upon. In some sense, the cons of TEEs haven’t changed, but developers’ understanding of them has. We’ll observe that this has held up for the other PETs to varying extents.
In short, the system of components (including the hardware, firmware, and your program) that you need to trust when executing code changes between different types of TEEs, thus the choice of stack isn’t universally agreed upon—even picking between SGX and TDX is far from obvious. All the while, toolchains like Gramine and Enarx are constantly evolving, so building smart contracts around the trust model of a given TEE implicitly is a bet on standards which could change at any given point in time.
TEEs eschew static, clear, and auditable cryptographic guarantees for a moving, vendor-defined hardware perimeter. So the more you rely on them, the harder it is to reason about who you’re trusting and determine if that trust can silently change, which is not true of pure cryptography.
Critically, the modern use cases for TEEs in crypto follow the lessons learned from Secret Network, SGX exploits, and the general shortfalls of the TEEs of yesteryear. Flashbots has been advocating for TEEs in MEV since they proposed their collaborative Ethereum block building network in late 2022. SUAVE, which eventually became BuilderNet, specifically leverages Scalable SGX and TDX for block-building where the need for low latency when building ephemeral blocks trumps absolute, everlasting security. The same goes for some of the newer onchain CLOBs which optimize for latency over all else. Whilst developing SUAVE and BuilderNet, the Flashbots team and others recognized that TEEs were broadly compatible with the trust model of rollups’ state ahead of settlement on Ethereum Mainnet. We’ve since seen a similar model on Solana with Jito’s Block Assembly Marketplace. Similarly, Turnkey’s use of Amazon Nitro TEEs demonstrate TEEs’ viability for the key storage of short-lived secrets despite lacking persistent memory.
AI finetuning has also broadly been a space where TEEs have been in production, given the need to remotely run proprietary models on even more proprietary data. As mentioned in the previous article, teams like Apple and Amazon have built their own inference hardware with TEEs, but critically, each of Nvidia’s ubiquitous server-grade GPUs after the H100 contain secure enclaves. This distribution effect of Nvidia’s GPUs having a TEE onboard has given rise to auditable AI through TEEs. Libraries like Phala’s Dstack have given developers a uniform experience for productionizing GPU TEEs, which is useful for teams building agents and running inference in applications where users might need to verify that a model is what it claims to be.
As of now, adding TEEs onto an already robust privacy app is a relative no-brainer as it adds 0-day or physical access as a form of conditionality to realize other weaknesses—the trouble is assuming robustness of the TEEless app. On the question of how developers go about achieving this by implementing TEEs into their stack, there are a wide range of competing frameworks: Gramine and Scalable SGX for Intel, AMD’s SEV, confidential VM platforms like Intel’s TDX, unified sets of APIs like those prescribed by the recent hardware agnostic TPM 2.0 libraries, and open-source frameworks like dStack that developers interact with on top of the hardware. All of these attempt to solve past vulnerabilities within the bounds of the TEE trust model. While this isn’t quite a standard of privacy, this diversity within enterprise TEEs can have some advantages, which we’ll note later.
Broadly, TEEs are more than just “good enough” for minimizing latency on ephemeral use cases but are structurally unfit to anchor a universal privacy layer as a single solution.
Over time, modern MPC implementations have evolved beyond academic curiosities into specialized tooling for latency-tolerant privacy applications. Production-ready frameworks (re)written in Rust, like MP-SPDZ, have enabled practical deployments where multiple parties compute on sharded secrets. For instance, identity checks using World’s iris scans leverage this property to access a distributed database of highly sensitive information in a compliant manner. Systems like World lean heavily on preprocessing techniques like those in BDOZ/SPDZ protocols, which amortize cryptographic overhead by pre-generating correlated randomness for later computations.
Crucially, projects now target niche verticals where MPC’s trust decentralization aligns with operational realities. Custody providers like Fireblocks use threshold ECDSA to secure institutional wallets, while privacy-focused chains like Namada employ MPC for cross-chain asset shielding.
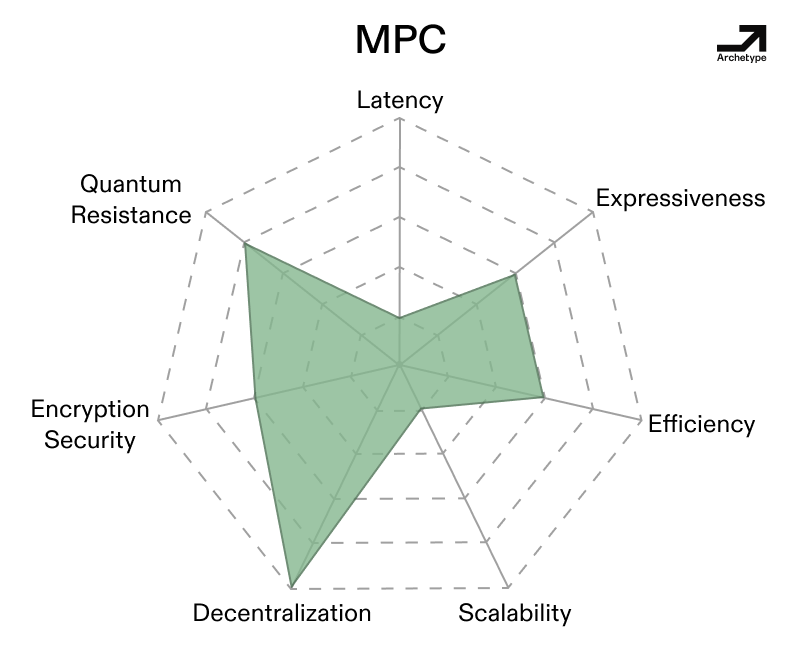
MPC inherently accommodates decentralized inputs, allowing multiple independent parties to securely contribute secret data according to the hardness of a given implementation without centralizing trust or control.
This capability enables truly distributed operations, naturally aligning with decentralization. Moreover, MPC implementations can achieve robustness similar to erasure coding by semi-redundantly distributing computations across several participants. If some nodes fail or act maliciously, the overall system maintains integrity by reconstructing outcomes from the remaining honest parties, thus providing strong redundancy and fault-tolerance. Additionally, recent advancements like Dan Boneh’s work on traitor tracing for threshold decryption reinforce MPC’s tradeoffs between communication overhead and collusion resistance by embedding uniquely identifiable markers in secret shares, allowing networks to detect and deter malicious collusion retroactively. Another area where MPC’s properties shine is in 2PC settings, wherein one party is the proposer, while the other is the verifier. In this specific setting, MPC takes advantage of natural trust assumptions and data asymmetries between proposers and verifiers, while being relatively performant. All in all, MPC at present has a unique strength in bridging crypto’s trustless ideals with practical, decentralized operational realities—supposing systems don’t use too few or too many nodes.
Along these lines, an Achilles’ heel of MPC continues to be the complexity in coordinating and bootstrapping a trustworthy network of nodes.
Most blockchain applications require serialized, low-latency operations, which is a poor fit for MPC’s networked compute model with a large number of nodes, as it introduces unavoidable delays as nodes synchronize state across geographies. However, using too few nodes increases trust and makes it relatively more easy to collude maliciously.
Much like Dan Boneh’s earlier-mentioned work, MAC-based authentication and cut-and-choose verification have emerged as guardrails for dishonest majority scenarios, though they add computational layers to an already heavy stack. For many MPC networks, additional computational complexity is a worthwhile tradeoff, since bootstrapping a fully secure network comes with lots of legal liability, when the companies who’d benefit most from doing so aren’t even in the business of building secure networks in the first place! These advances for dishonest majorities reflect how MPC’s trust mode has matured—modern networks combine cryptographic proofs and economic disincentives to harden collusion resistance and are no longer purely reliant on ex-ante solutions and statistical honesty assumptions.
Despite progress, MPC’s core tensions endure. Networks with 10+ nodes achieve Byzantine robustness at the cost of AWS-tier operational expenses, while smaller node sets risk centralization. In this sense, a 3-party MPC wallet offers little trust advantage over a similarly sized multisig, though it doesn’t reveal the participating parties and requires no buy-in from the chain. Meanwhile, the rise of FHE and private co-processors threaten to eclipse MPC in scenarios where privacy must coexist with low latency.
MPC is the “right” solution for key management in crypto.
The chasm between MPC’s theoretical potential and practical utility remains widest in latency-sensitive environments, which flows into use cases. While projects like Dfns exploit MPC for multi-party wallet recovery (a naturally asynchronous process), most DeFi use cases—liquidations, arbitrage, AMM swaps—demand millisecond-level finality. As mentioned earlier, some level of latency is inherent with MPC’s model of consensus across distributed nodes, but this effect is multiplied over multiple rounds of communication, as shown below.
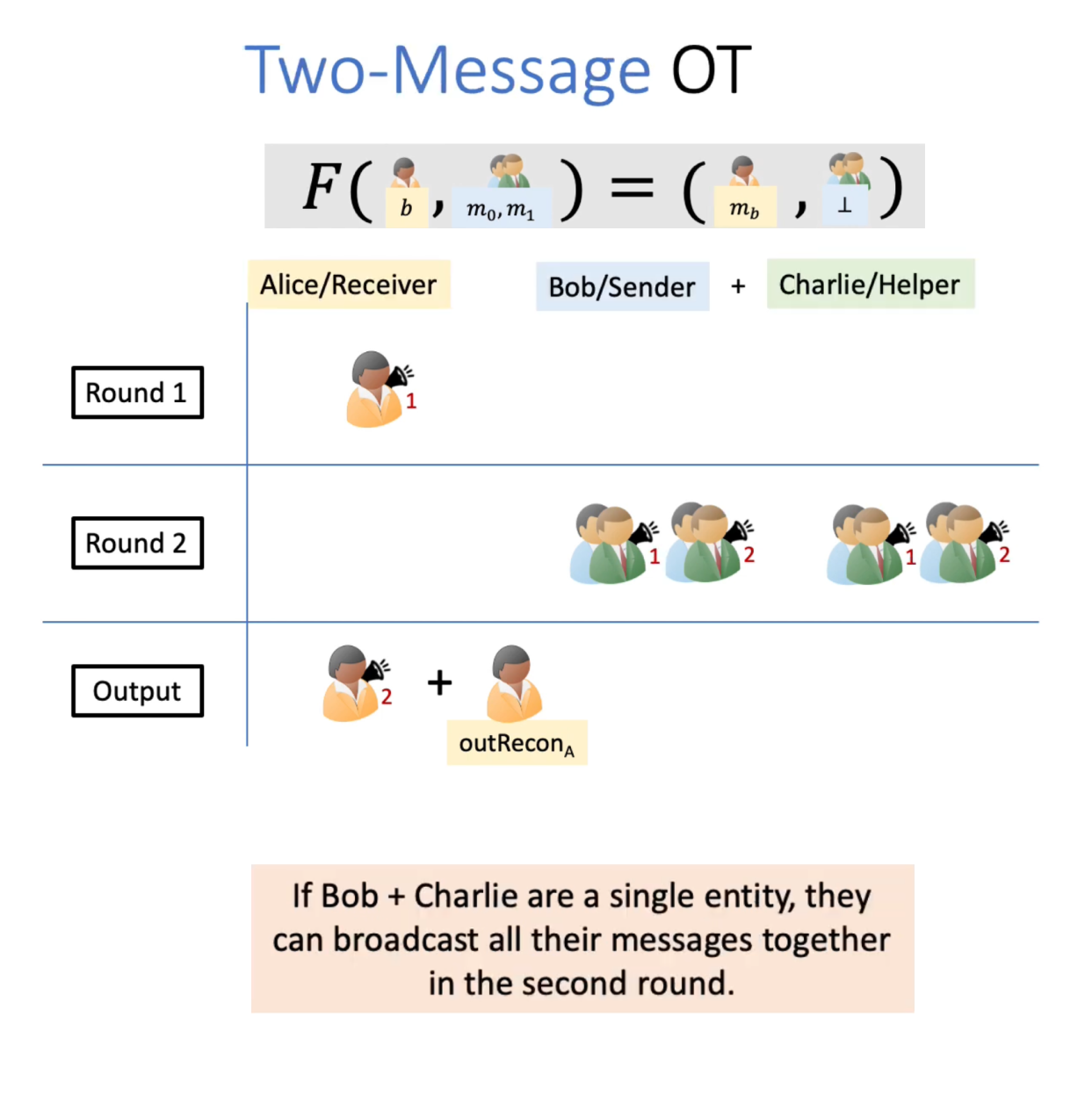
To reiterate, you can think of MPC like a bunch of computers using shards of state across a distributed network and then coordinating to compute over it without ever putting it back together in a single place. This works for super computers on parallelized operations (for data science people think Dask vs Pandas) and problems that look like torrenting (picking peers to collectively own and assemble chunks of data). Problems of this shape appear in many peer to peer settings, including payments and semi-local social graphs like those in dating apps and local messaging services. But most problems in crypto are somewhat serial and inherently collaborative, which means that we need to reassemble shards of data fairly often, equating latency.
All that being said, MPC works really well for latency insensitive use cases with a small number of parties who all contribute secret data, which comes up regarding FHE decryption in the next part. It’s for this reason that MPC is ubiquitous in managing keys and identifying data—without MPC to provably shard data, it would be impossible to store iris and passport data on World in a manner that complies with privacy regulations across the world.
As such, MPC is the only PET capable of truly decentralizing encrypted compute and ultimately bridging crypto’s trustless ideals with the messy reality of coordinating computations across institutions.
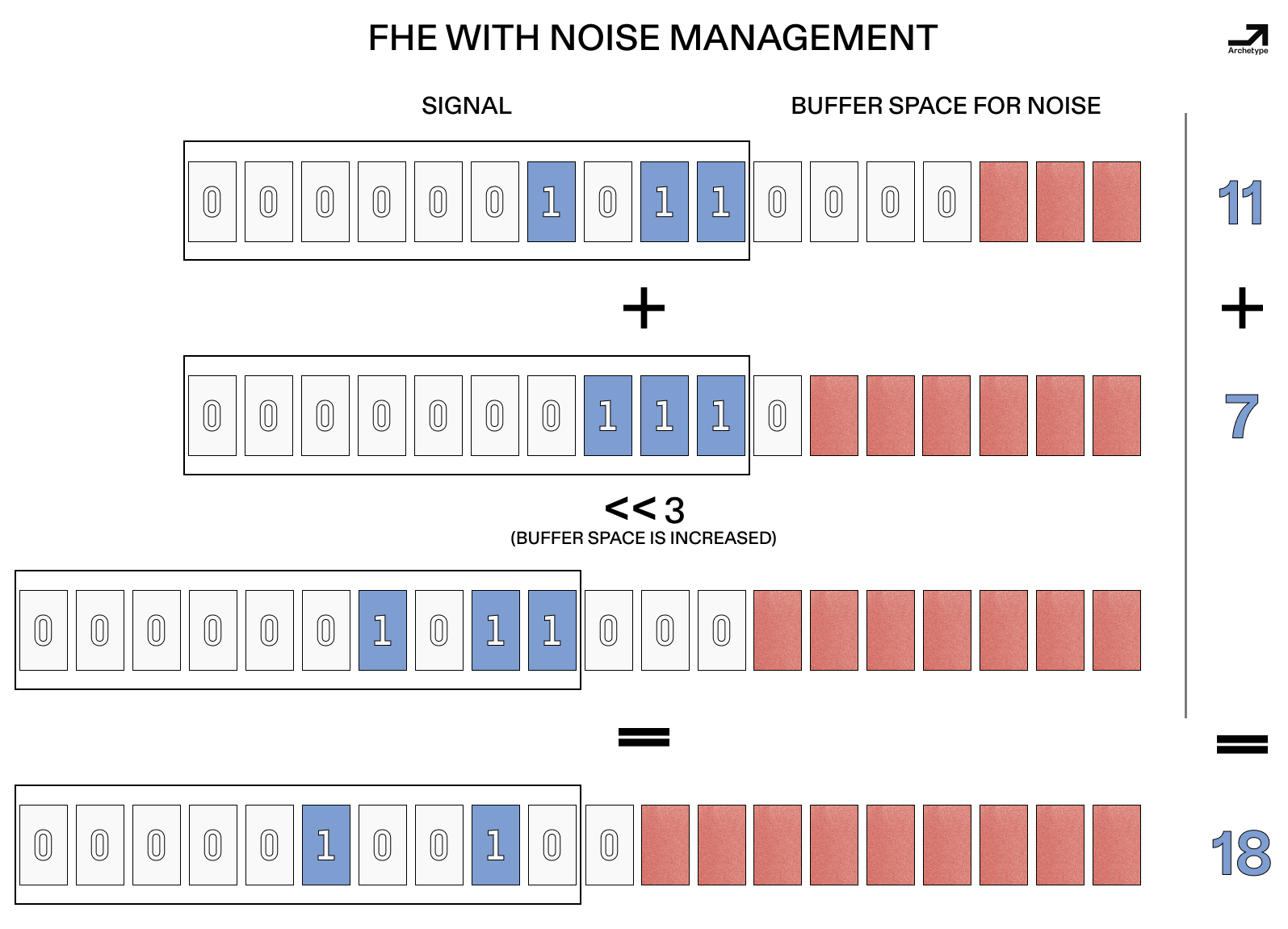
Today’s FHE landscape is defined by competing visions of standardization and a race to tame its key flaw—computational bloat on single operations. Modern FHE schemes use complex math primitives like polynomial rings over finite fields as a base for binary operations while creating cryptographic noise which must be managed through techniques like bootstrapping, as we mentioned in the last article. Zama’s Torus-based FHE (TFHE) scheme is currently the most widely adopted FHE scheme for crypto applications. TFHE’s wide adoption has partially resolved the “format wars” we pointed out in the previous article by offering a unified compiler for leveled and bootstrapped circuits.
In resolving this format war with TFHE, Zama has made bootstrapping faster and is currently monetizing that advancement with Zama Protocol and their licensing model where they receive a portion of protocols’ tokens in exchange.
As for feasibility outside of TFHE, research on new bootstrapping schemes like CKKS is a hot subfield of academic cryptography, which increases the possible size of FHE operations which can be done without bootstrapping. This could ultimately make for a wider set of fast and private FHE apps in a zkVM-esque boom in 2-ish years, with onchain applications bearing fruit in 3-5 years.
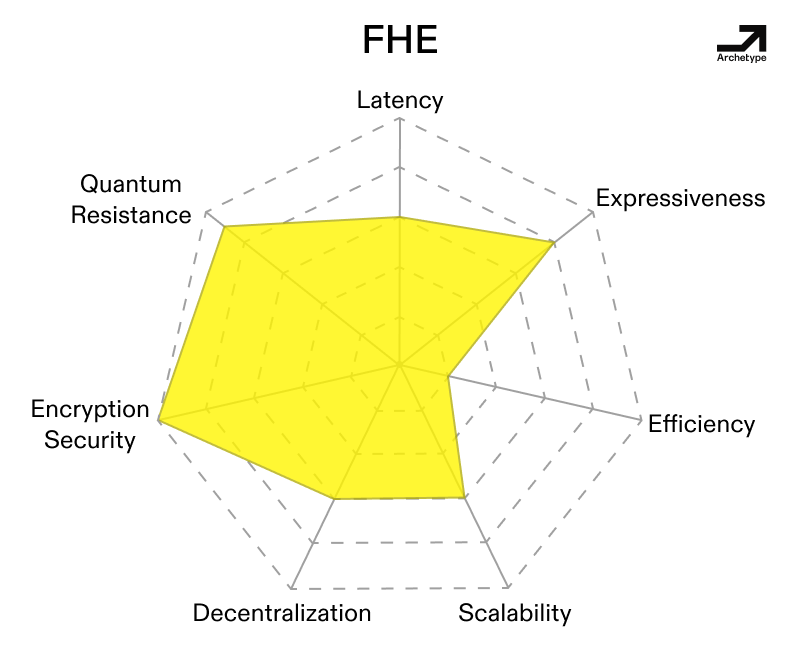
FHE is optimal for expressive computations involving many operations.
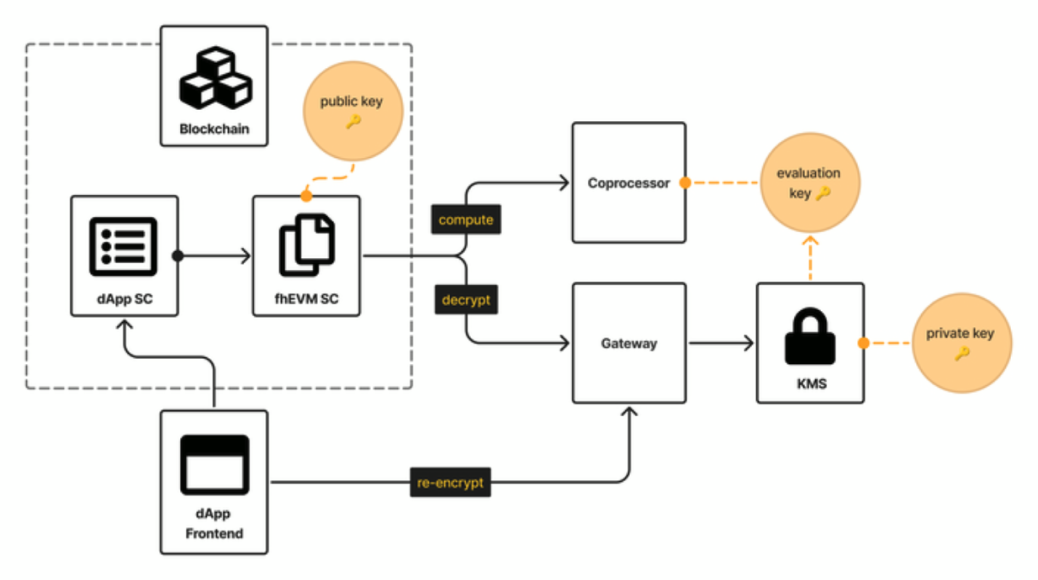
Most of the early privacy VMs originally started life using FHE because they prioritized expressiveness on par with the EVM while being private. As proofs of concept, speed and cost weren’t top priorities. Zama’s Solidity-complete fheVM is a great example of what FHE enables in this context—relative to other PETs, FHE is comparatively fast over expressive computations involving many operations. These applications theoretically cover most things we think of as onchain computation, including multifactor identity and data marketplaces. This comparative advantage largely comes from something called symbolic execution, which involves running analogs of arbitrary computations offchain until users need to decrypt their results. In contrast, other PETs would require more rounds of communication and significant coordination overhead and latency for intermediate syncs of state.
FHE’s computational overhead currently makes it hard to use as an onchain privacy solution for general-purpose applications.
The core challenges from the early days of FHE persist—noise and computational cost are high. When using FHE for too few computational steps, the time and cost of wrapping and unwrapping data with an MPC decryption committee isn’t worth it. But when using FHE for too many complex computational steps, you run into issues with noise and still need to bootstrap, resulting in time and cost. This has limited FHE to specialized use cases where computational cost is less critical than perfect privacy guarantees. In this sense, FHE use cases feel like those of a coprocessor by virtue of being too expensive for all tasks and thus intended for certain tasks to be offloaded to an FHE VM.
FHE has a large fixed cost, but it can be amortized.
In contrast to the other PETs, FHE allows for local and arbitrary computation on encrypted data, functioning like an encrypted general-purpose computer using math rather than solely offloading privacy to social coordination. As such, most code, including smart contracts, can theoretically be run with FHE as long as a compiler exists and offchain symbolic computation can be used for a given use case.
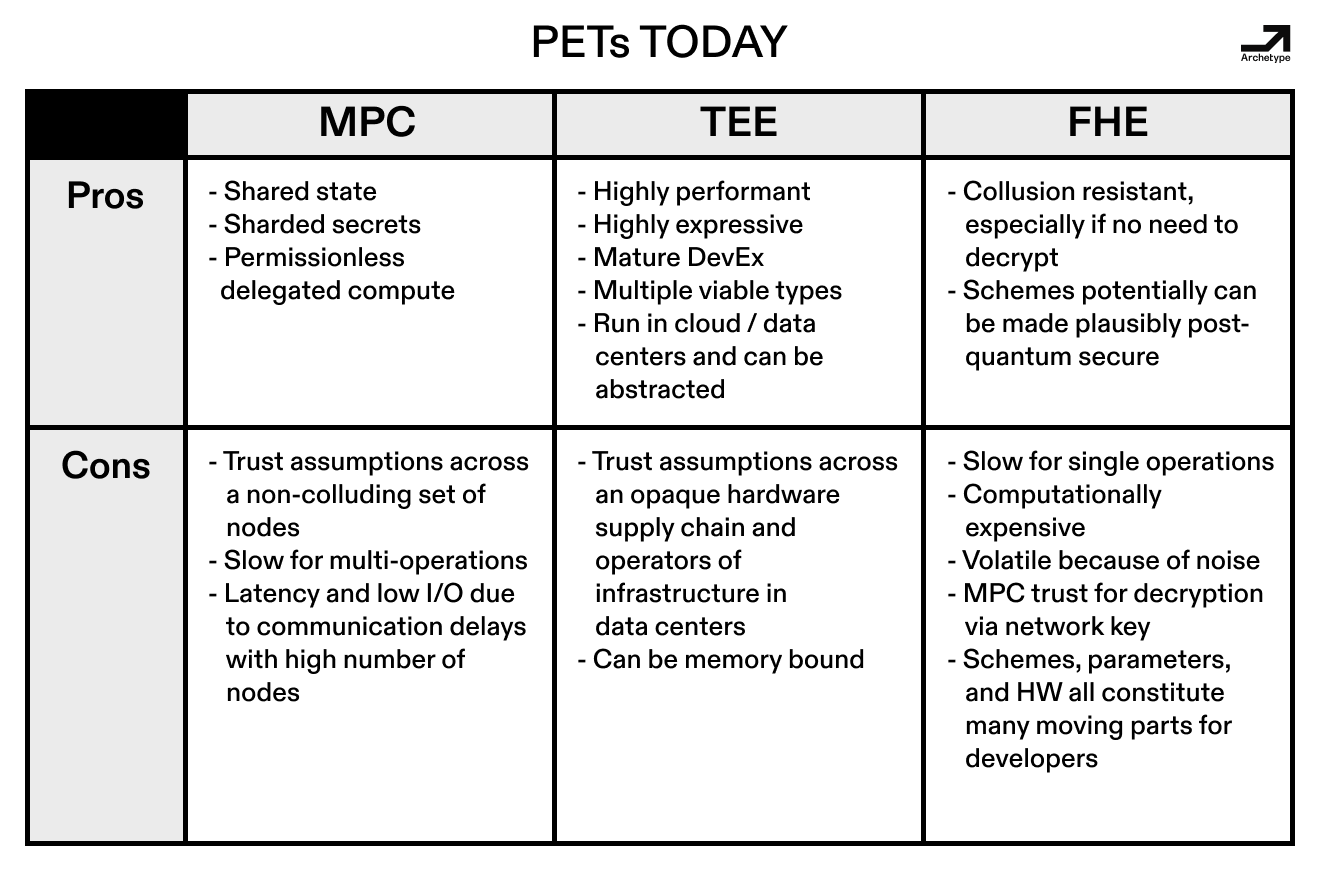
Given the sharp tradeoff space for today’s PETs, a multimodal or hybrid approach where applications combine multiple PETs seems to make a lot of sense. Based on the pros and cons above, a feasible multimodal system using distributed trust today could come from FHE with key management distributed over multiple TEEs or broad 3PC on heterogeneous TEEs—Signal’s key recovery system looks somewhat like the latter, and Georgios’ article on private hardware would classify this as level 5 if the TEEs were open sourced.
So what lies on the horizon if PETs don’t structurally improve? Here’s a quick rundown of that world.
On the TEE front, various flavors of closed source designs continue to be deployed alongside other compute resources on distributed server racks for the foreseeable future. Similarly, MPC continues to use things like Oblivious RAM to iterate around coordination costs and collusion beyond the trusted 2-3 party compute that’s currently feasible. Finally, most crypto projects building on FHE continue to use TFHE while waiting for FPGAs and ASICs from existing FHE teams like Zama or hardware teams like Fabric.
While each technology excels in certain situations, these problems continue to hinder them from enabling a successful Privacy 2.0 across contexts. But what happens to latency, expressiveness, efficiency, scalability, decentralization and the other attributes we looked at when we combine their powers?

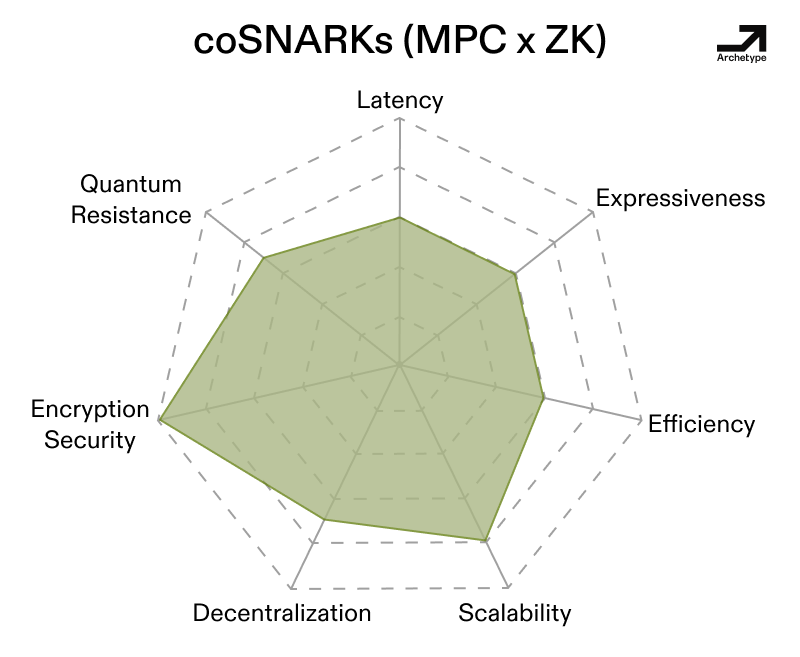
Systems like Signal’s secret key recovery system (pictured way below), Trinity (a combination of garbled circuits, KZG, ZK), Hallucinated Servers, multi-party FHE (MPC + FHE), verifiable/ auditable MPC (MPC + TEE), as well as coSNARKs (which combine the strengths of MPC + ZK by sharding the witness of a ZK-SNARK across an MPC network) are all in production and leverage multiple PETs. Each of these combinations results in an averaging out of the PETs’ spikes into more well-rounded profiles of features.
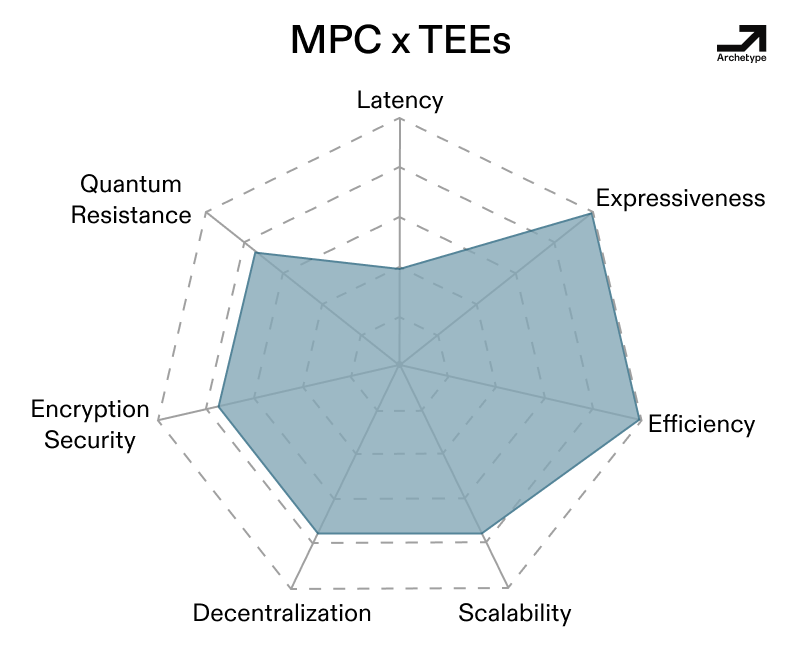
However, latency can be a concern with hybrid systems, as shown above. Just like with vanilla MPC, round complexity, or the number of messages needed to do things in a system, can be a factor, just like the communication overhead that we noted earlier. Further, the design for each of these hybrid systems ends up not being general purpose even if they’re less spiky. This isn’t a bad thing, as the limitations become features in some sense (see Trinity’s 2pc scheme and the unique social stuff designed around its initial restrictions on proximity).
There are a few core takeaways here. Building a hybrid system does come with some additional costs and inefficiency, the most obvious being communication overhead and round complexity. This much is relatively intuitive, as adding TEEs to a system adds conditionality to trust assumptions—in order to compromise a combination including a TEE, you need a zero-day bug in a TEE or side channels in addition to another exploit. In this sense, adding very lightweight TEEs to an FHE or MPC stack enables secure remote attestation for nodes, ultimately making the stack verifiable. Similarly, developers can sidestep MPC’s limitations by treating MPC as a component of hybrid stacks rather than a full-stack solution—coSNARKs hybridize ZK proofs with MPC to offload intensive computations.
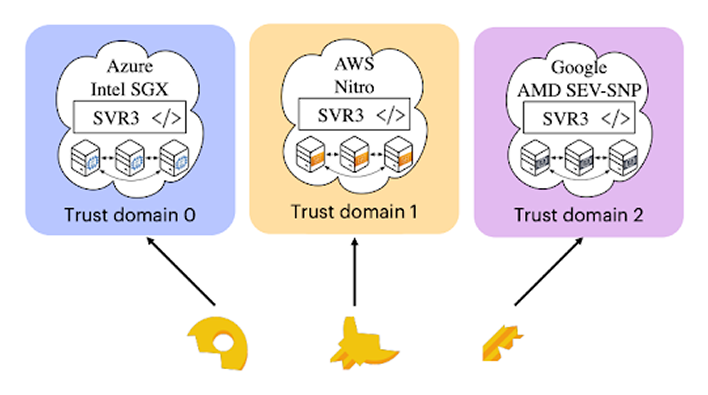
And hybrids aside, one might wonder what has changed with regards to the problems which we outlined at the start: the hardware vulnerabilities of TEEs, the coordination issues of MPC, along with the efficiency and noise of FHE? With TEEs, data center deployments for today’s TEEs are broadly considered safe enough for certain use cases, and open-source TEEs continue to be an area of research. With MPC, generalized networks are being established to lessen the burden of bootstrapping secure networks per MPC applications, while new schemes promise efficiency improvements. Finally, with FHE, ASICs and newly proposed schemes show promise from the perspective of reducing noise proliferation and making noise management less burdensome. In short, the structural problems of these PETs have gotten monotonically better over time, but not to the point where they can disappear from relevance.
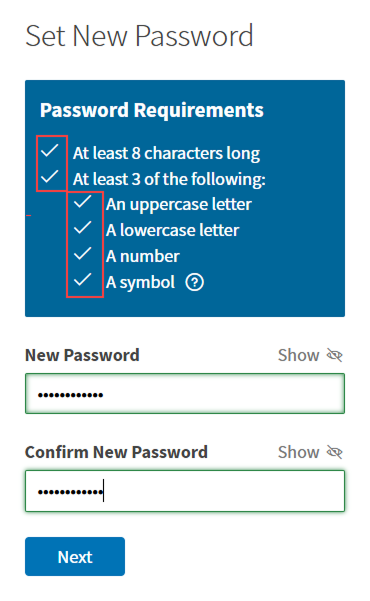
With all of this in mind, I predict that in the medium term, single PET systems will become a rarity in the medium term and we will see developers generally adopt a threshold for hybrid “pick 2 out of n” PETs like complex password requirements.
But much like with passwords vis a vis passkeys, social and post-quantum security abstractly looms behind today’s privacy systems. Post-quantum cryptography is an ongoing problem in many regards, and expensive to implement. Even then, it’s unclear when q-day will be or the extent to which quantum is an issue in the nearer term. But tomorrow’s tools might actualize today’s bleeding edge research.
For instance, the, well, solvable nature of abelian solvable groups might compromise the quantum security of FHE schemes as we know them. TEE security contingent on trusting manufacturers might become too much of a honeypot for destructive analysis. And sidechannel attacks might become relevant to MPC and FHE via memory attacks.
These problems all define the future of our familiar cast of TEEs, MPC, and FHE, as well as those of new heroes and sidekicks like Indistinguishability Obfuscation (IO), Physically Unclonable Functions (PUFs), Oblivious RAM (ORAM), and Hypergraphs. We’ll dig into these more next time around.
Many thanks to Ais Connolly, Arnauld Brousseau, David Wong, Nitanshu Lokhande, Rishabh Gupta, Rand Hindi, Katie Chiou, Dmitriy Berenzon, Tyler Gehringer, and others for looking and conversing over various ideas, outlines, figures, and drafts.
—
Disclaimer:
This post is for general information purposes only. It does not constitute investment advice or a recommendation or solicitation to buy or sell any investment and should not be used in the evaluation of the merits of making any investment decision. It should not be relied upon for accounting, legal or tax advice or investment recommendations. You should consult your own advisers as to legal, business, tax, and other related matters concerning any investment or legal matters. Certain information contained in here has been obtained from third-party sources, including from portfolio companies of funds managed by Archetype. This post reflects the current opinions of the authors and is not made on behalf of Archetype or its affiliates and does not necessarily reflect the opinions of Archetype, its affiliates or individuals associated with Archetype. The opinions reflected herein are subject to change without being updated.
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur.
Block quote
Ordered list
Unordered list
Bold text
Emphasis
Superscript
Subscript
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur.
Block quote
Ordered list
Unordered list
Bold text
Emphasis
Superscript
Subscript



