
Over the previous two parts of this trilogy, we’ve concluded that 1) crypto needs private shared state and 2) it will be achieved via hybrid stacks (combinations of TEEs, MPC, FHE, and ZK) in the medium term.
But that still isn’t a stable outcome for the longer term.
These hybrid stacks can achieve high levels of security and privacy, but they also require vastly different sets of developer and user behaviors. It’d be like if every lock and key you encountered in your daily life was a distinct puzzle operating on different combinations of technologies. This actually happened, as locksmiths of the eighteenth century competed with each other to make the most elaborate and secure designs possible. Many of these were incredibly secure, but were also overly complex to the point of being unusable. Even if they had their keys, users basically needed a different set of knowledge and skills to open each individual state-of-the-art lock.
Eventually, a desire for cheap mass production, replaceability, and an understanding of what reasonable levels of security entailed all gave way to what we now think of as a standard lock, using pin-tumblers and cylinders even though more robust methods exist.
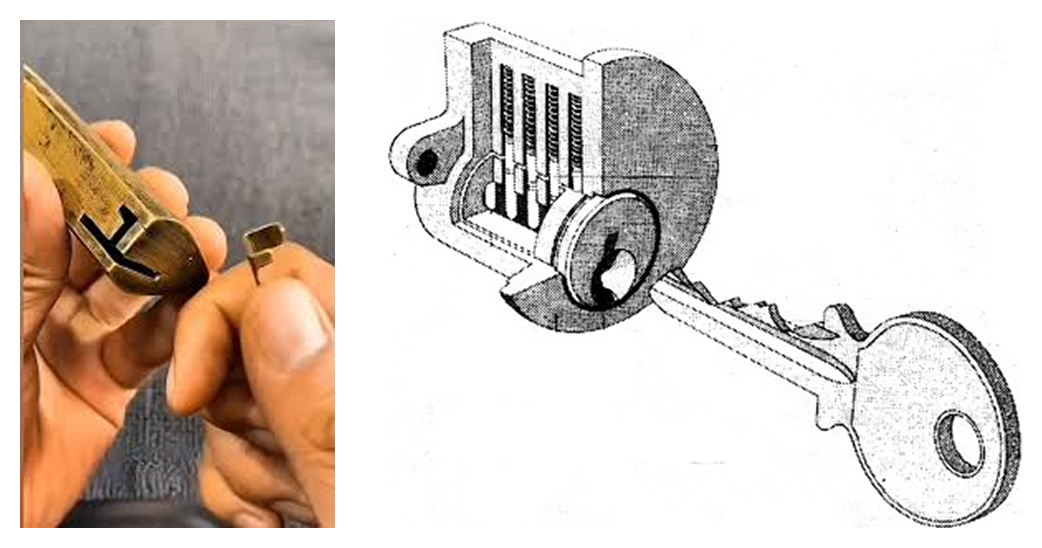
And this is what onchain privacy needs.
To bring it back to privacy tech, we need a base-layer protocol that can wrap around any arbitrary action to add a reasonable level of privacy, auditability, and verifiability without fundamentally changing how the action is currently done. A Universal Cryptographic Protocol (UCP) akin to HTTPS / SSL on the internet that bespoke use cases can layer their own notions of privacy on top of.
While this unfortunately remains just out of reach using today’s PETs as they currently exist, they are evolving rapidly. All of these technologies, as well as net-new ideas like Indistinguishability Obfuscation (iO) that we’ll cover later, are still candidates for our Universal Cryptographic Protocol.
To figure out which current tech has the best shot of solving the UCP puzzle first, I’m going to break down the gaps between the current implementations of TEEs, MPC, and FHE, and what “well-rounded” implementations that could be used universally might look like. Less kiki, more bouba.

In the longer term, the winner here will take the shape of an *almost* one size fits all solution that has all of the following:
From then on, privacy being on by default will come down to regulations and user preferences, rather than technology.
The hurdles preventing TEEs from being a no-brainer one-stop shop for verifiability and privacy have been physical trust assumptions and risk vectors from manufacturers and operators alike. So to turn well-rounded TEEs into a UCP, they would need to make the trust assumptions and roots of trust less opaque to end users and developers.
TEEs fail socially before they fail cryptographically. The problem isn’t so much that enclaves can’t perform secure computation, but that users can’t convincingly reason about who they’re trusting because of the opaque supply chains behind TEEs.
Fortunately, TEEs secured by PUFs (Physically Unclonable Functions) solve this at the root (of trust, that is). This sub-category of TEEs are built to open-sourced standards across hardware and firmware, and manufacturing compliance at each step can be verified by the end user and by the network at large.
In other words, the enclave stops being “Intel says this is safe” and starts being “anyone can verify this is the exact thing they expect.” That’s the first step toward making TEEs practically composable in serious cryptographic systems rather than quarantined in trusted silos.
Part of the blueprint of well-rounded TEEs is the firmware that they run and, specifically, treating it like a consensus layer with minimal trust assumptions. People building networks which incorporate TEE nodes accomplish this by preventing the operators of these TEE nodes from downgrading to firmwares with known exploits and making sure that firmware configurations, or builds, can be reproduced in isolation and therefore independently verified by users and third-party auditors.
The net effect of incentivizing participation in a broader network is that the TEE’s operator no longer has unilateral control over what code is actually running in an enclave.
But what if the magnitudes of value in play make it impossible to trust hardware? Dining Cryptographer Networks (DCNets) and systems like ZipNet attack traditional TEEs' brittle failure mode directly by changing the threat model towards MPC. They assume enclaves are at best honest-but-curious and at worst malicious, and then engineer the system so that privacy survives anyway. Sensitive state is never concentrated in a single enclave; instead, it is sharded across a small collection of tightly controlled TEEs, each operating under heavy physical and network restrictions, where no single machine ever holds enough information to betray the system.
In doing so, these designs pull TEEs into a space that traditionally belonged to MPC: trust is no longer binary, it is distributed. But unlike classical MPC, the computation still runs inside enclaves, preserving the latency and programmability advantages that make TEEs attractive in the first place. The result is less a retreat from hardware security and more an evolution of it, moving from trusted execution to constrained execution under cryptographic supervision.
If PUF-secured TEEs are about anchoring trust in hardware, DCNet-style designs are about reducing how much trust the hardware gets in the first place.
Collectively, these upgrades would make for a viable TEE-based Universal Cryptographic Protocol, one that:
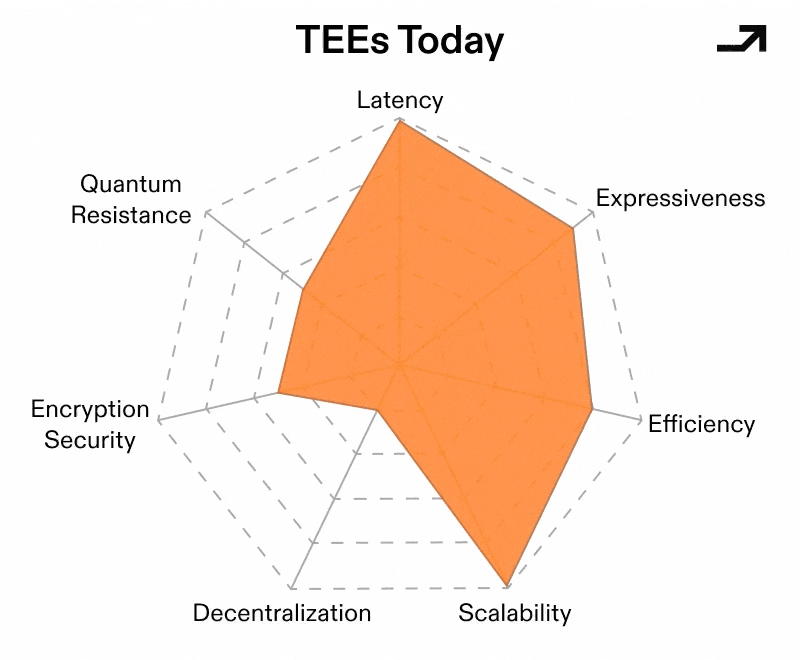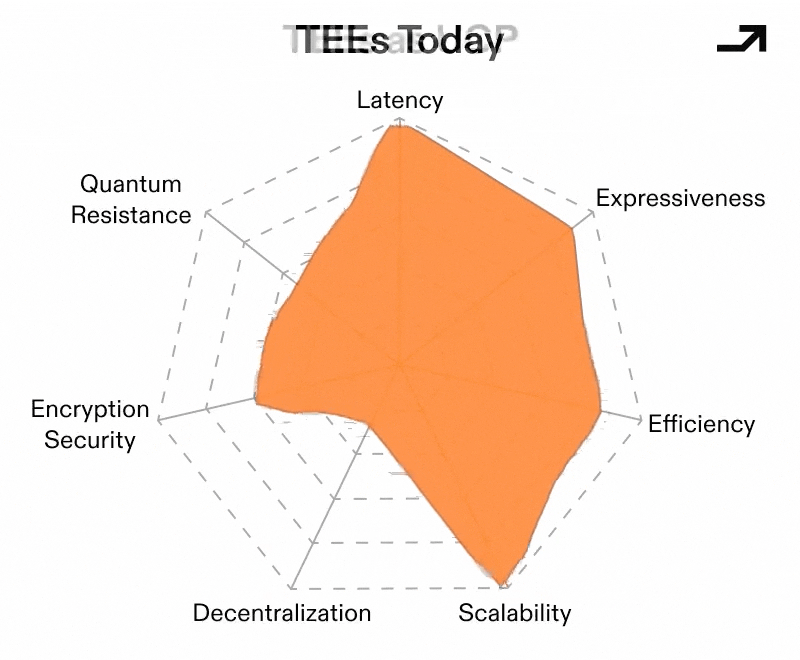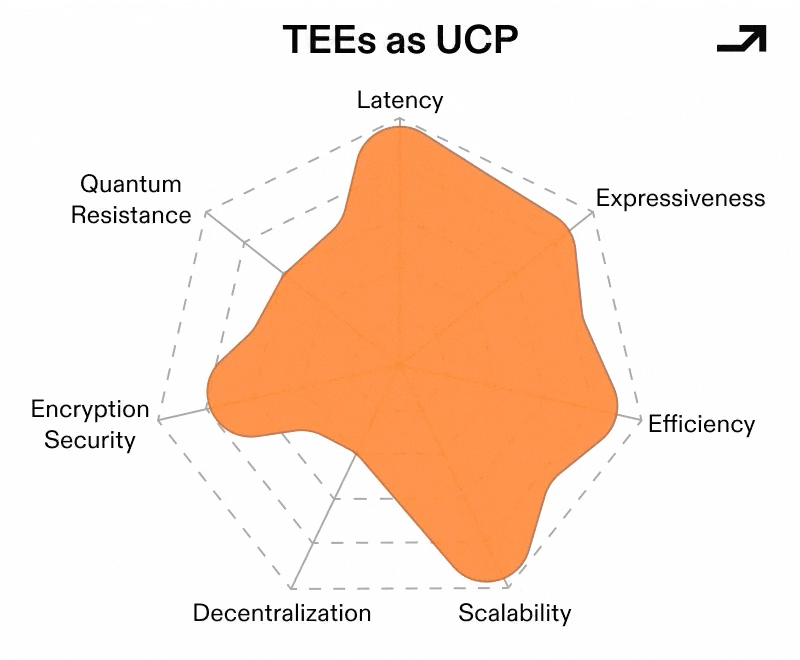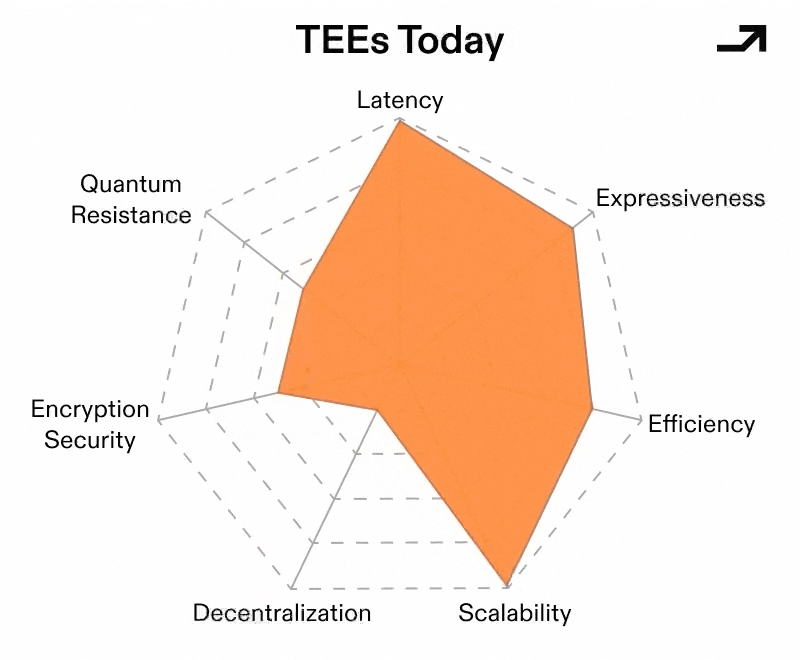
To be clear, a TEE-based UCP can’t assume hardware will always be perfect, but it’s designed around staying secure when hardware is only mostly honest. In that world, adversarial operators, supply-chain uncertainty, and side-channel leakage stop being existential threats and become bounded risks. And once TEEs can tolerate those conditions without forfeiting privacy, they stop looking like a fragile optimization and start looking like the only abstraction capable of supporting general-purpose private computation at scale.
The binding constraint holding MPC back from being more widely used has always been latency, owing to the number of times nodes in an MPC network need to communicate with each other. Critically, latency scales with decentralization, and naïve protocols become impractical once parties are geographically distributed. As such, the paths that make MPC into a UCP focus around reducing the number of rounds of communication for the same workload across the same number of nodes, with the result being less latency while holding trust constant.
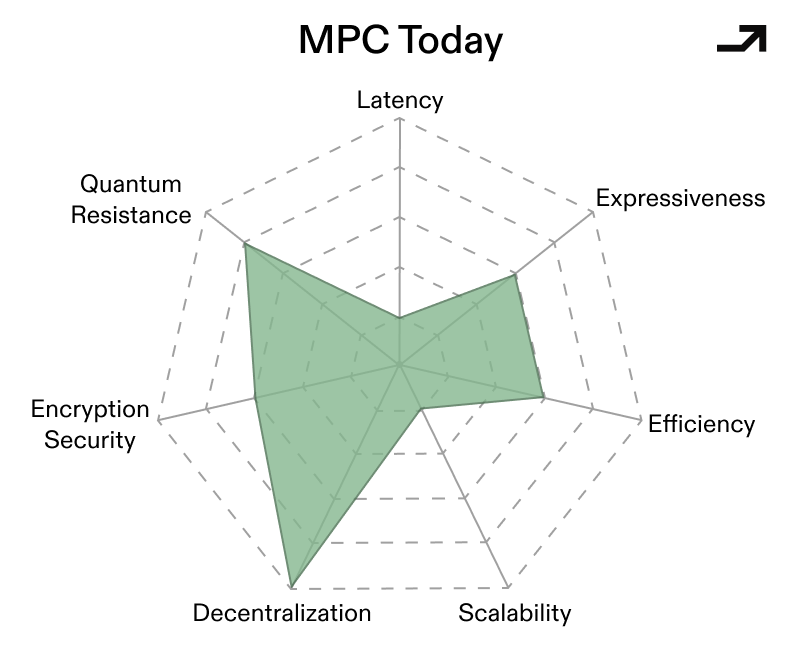
Early MPC protocols operated over finite fields, which made general computation awkward and expensive. More recent constructions move MPC to operate directly over rings (e.g. standard 32-bit or 64-bit integers) as opposed to symbolic operations over primes, which allows for native integer arithmetic and bitwise operations. Crucially, newer ring-based protocols (like SPDZ2k) leverage this technique to achieve very low, and sometimes near-constant, round complexity that keeps latency low even as complex tasks scale.
A large chunk of MPC’s cost comes from coordinating the nodes in a given network rather than the raw computations to solve a given problem. MPC schemes based on Vector Oblivious Linear Evaluation (VOLE) flip this model by pushing most interaction into an offline and offchain preprocessing phase, where correlated randomness is generated ahead of time. This then makes the online portion of computation more lightweight with fewer rounds and fewer messages, which translates into less latency.
Collectively, these advances would make for a conditionally viable MPC-based Universal Cryptographic Protocol. MPC still performs best when, in a standardized form:
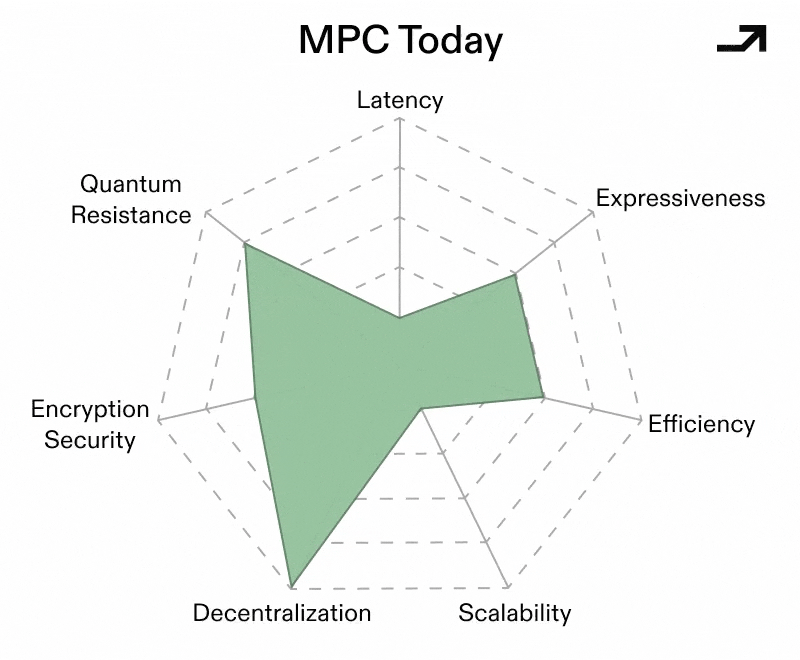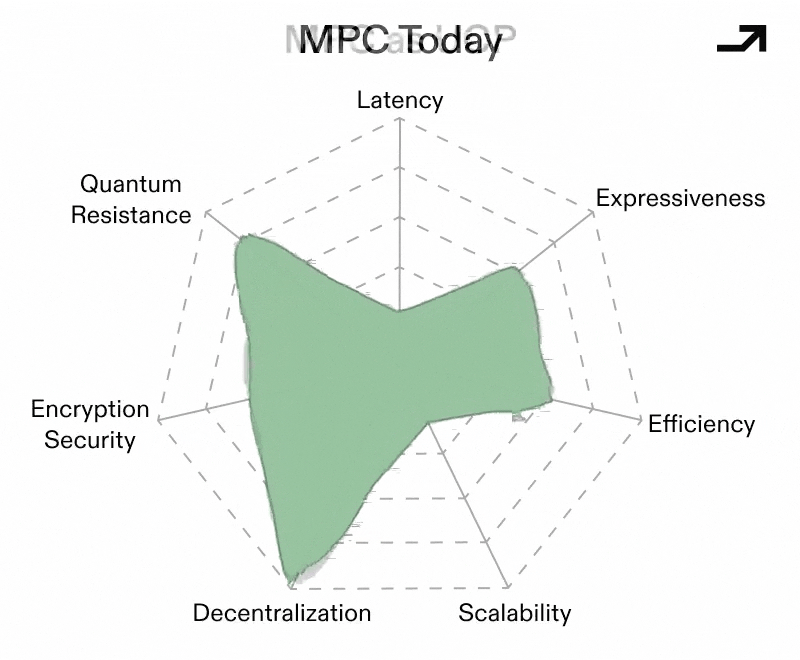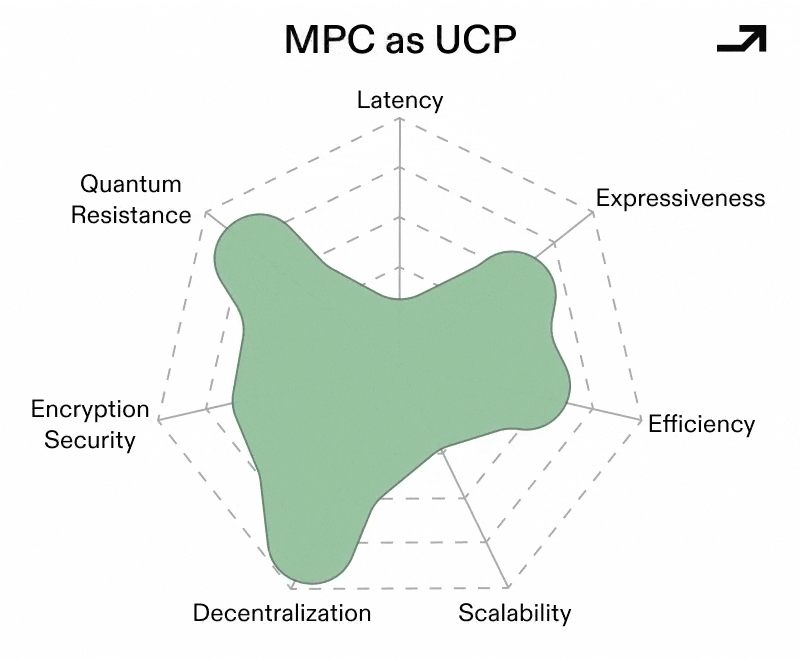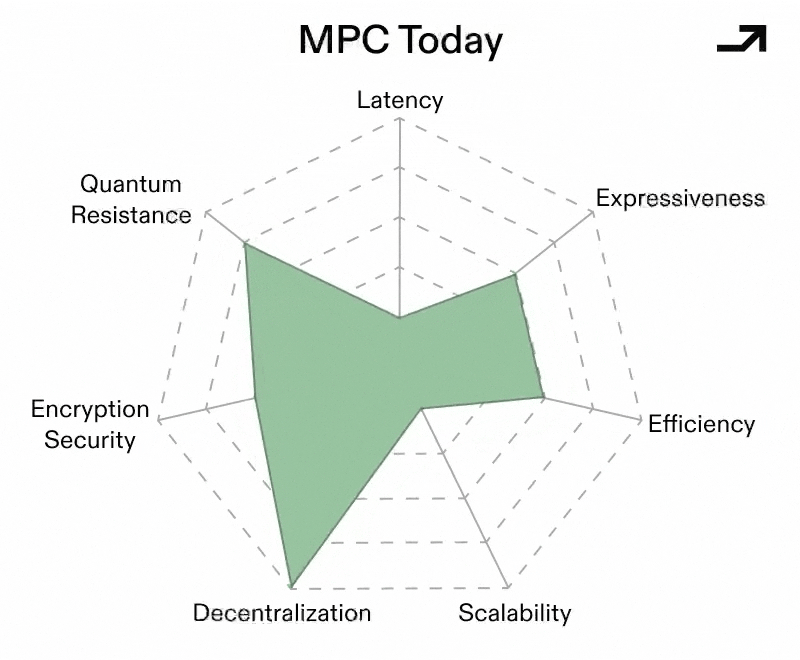
Even then, an MPC-based UCP is unlikely to be universal in the absolute sense. But as a protocol for distributed, high value, and potentially adversarial computation, well-rounded MPC protocols are closer to that role than ever.
FHE’s primary hurdle to date has been relatively high computational costs, both on and offchain. These costs stem from FHE’s noise accumulation and bootstrapping, which is then multiplied (potentially super-linearly) through the scale of the computation into monetary cost. This cost compounds with program depth and can turn “general computation on encrypted state” into something that is technically possible but economically absurd. As such, current approaches to FHE have focused on techniques like symbolic computation and coprocessors, which minimize cost by shifting the computational load of FHE offchain.
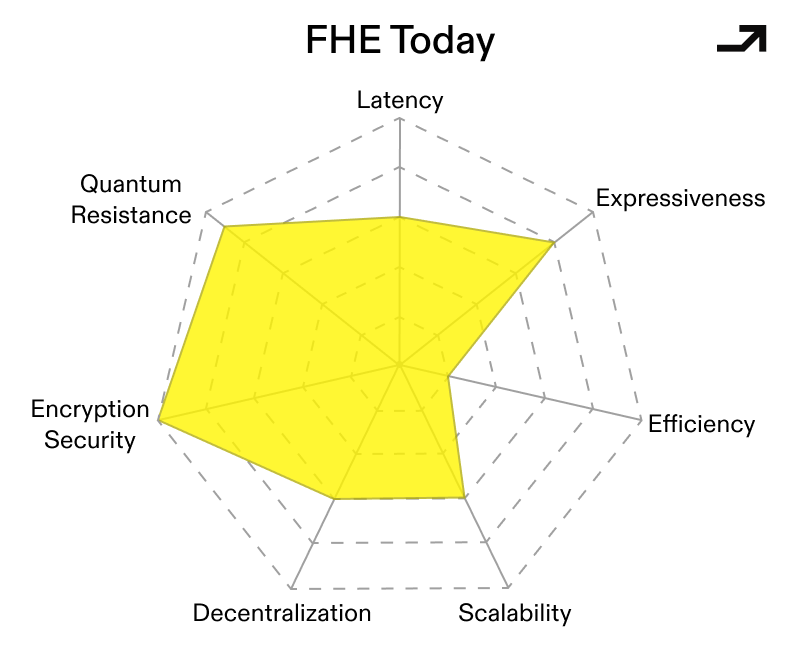
The core bottleneck in many FHE implementations is that the most important operation to scalable FHE, the noise resetting bootstrap step, also becomes the most frequently paid tax. Circuit-based bootstrapping is one attempt to change the shape of that tax: instead of repeatedly paying for expensive bootstraps as a routing primitive, the goal is to restructure evaluation so that more work is expressed as cheap, highly parallel operations. Bootstrapping is then used more strategically and with a program’s execution taken into account.
A related improvement vector is managing bootstrapping upfront via a compiler. By factoring bootstrapping schedules at compile-time, you can keep encrypted programs within feasible noise/scale budgets without requiring every developer to become an FHE parameter wizard. In other words, FHE compilers push us towards FHE being a well-defined compilation target with guardrails rather than hand-tuned cryptography.
If one squints at compiler-based bootstrapping, the heavy linear-algebraic work with a lot of structure and parallelism starts to look like a standard kernel workload where ASICs and GPUs shine. This doesn’t “solve” FHE’s cost problem, but it changes the curve even in a world where none of these other changes happen. In that world, FHE might still be expensive, but not prohibitively so for a larger class of workloads. There’s been quite a bit of development, including a hardware accelerator from Intel unveiled on March 10th, that claims to improve performance by 5000x.
If a Universal Cryptographic Protocol is meant to “wrap” existing apps, then key management and decryption policy become a core part of UX. Programs, like other things, can be split into functions. Let’s then imagine a version of FHE with multiple keys, where each one is tied to a single function within a set of functions. Keyholders can then use individual keys to selectively decrypt evaluations of their corresponding functions from their encrypted inputs. In a nutshell, that level of granularity is functional encryption and its utility.
Functional encryption can be thought of as a way of making programs which have multiple decryption keys that can decrypt each function within a program. In aggregate, this means that functions can be decrypted and audited before being used to compute things.
Functional Encryption, as an adjacent idea, makes FHE systems feel like programmable access control: instead of decrypting everything, you decrypt only what a policy allows (e.g., a predicate, an aggregate, a view). In practice, this doesn’t replace FHE, but it creates an ability to selectively define who learns what—and when from an FHE scheme, without ever needing to decrypt any otherwise unneeded data.
Collectively, these advances sketch a conditionally viable FHE-based Universal Cryptographic Protocol, one that:
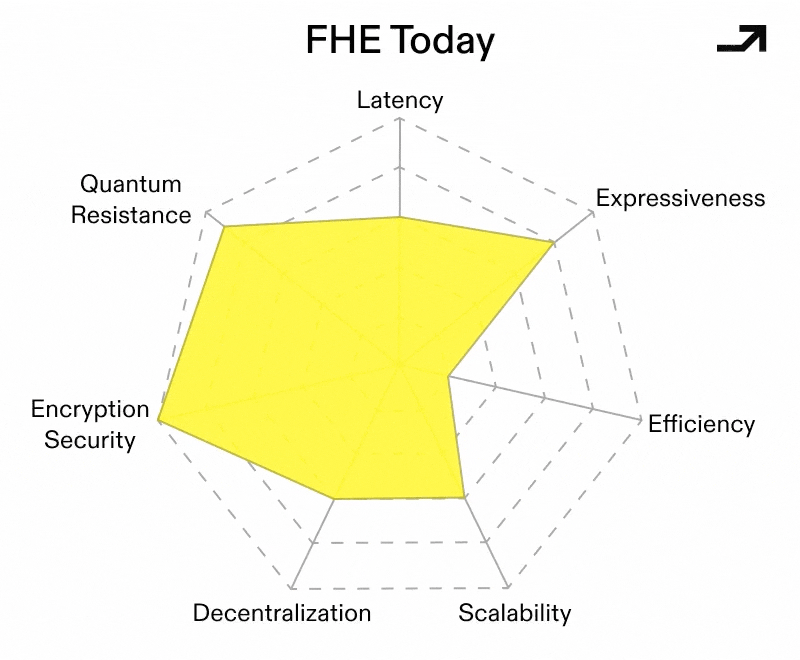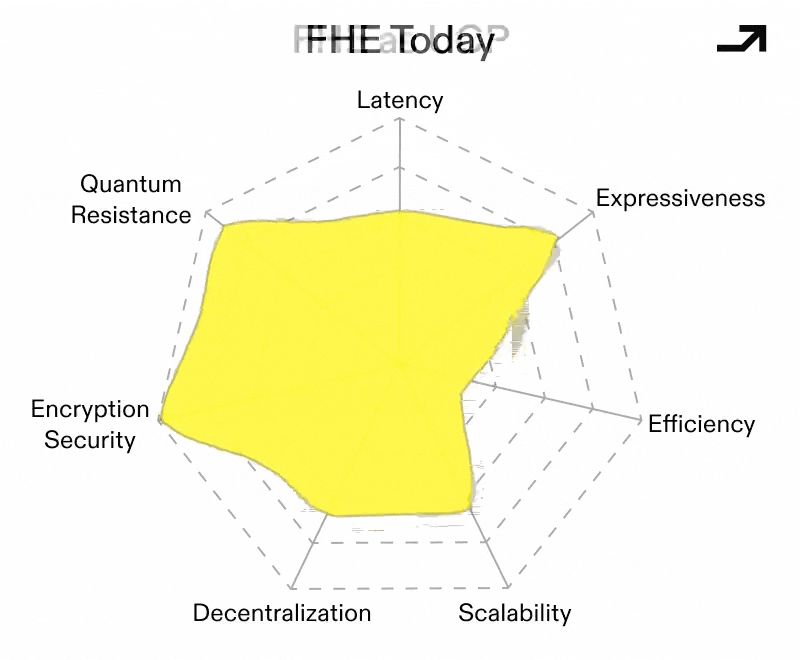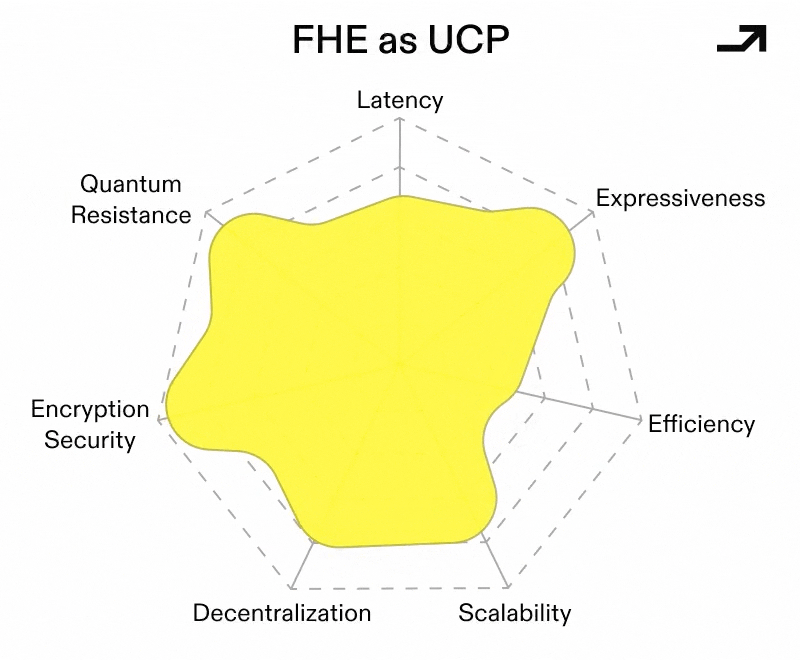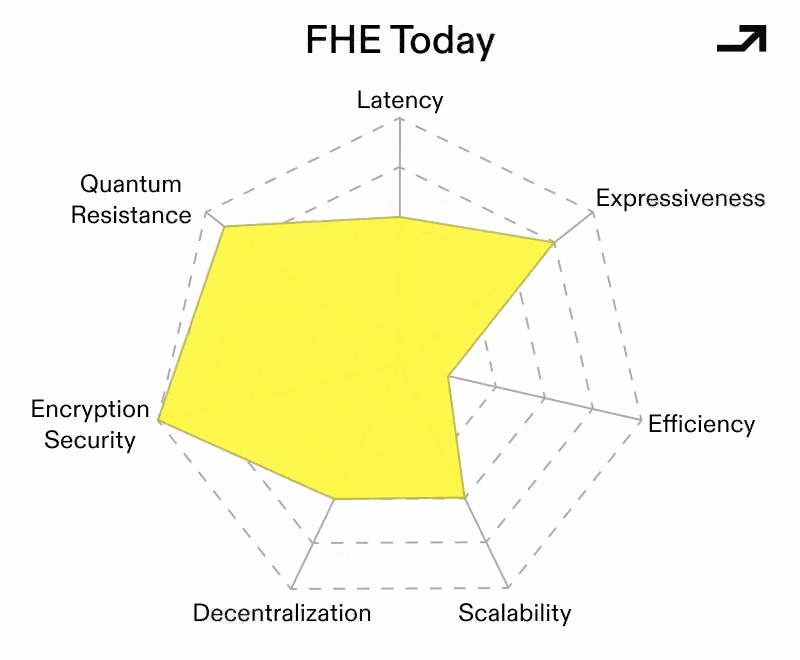
If FHE is to become a serious substrate, it needs shared expectations around security levels, parameters, and interoperability. NIST has been tracking FHE as part of its Privacy-Enhancing Cryptography efforts, and the community has also been organizing around standardization initiatives.
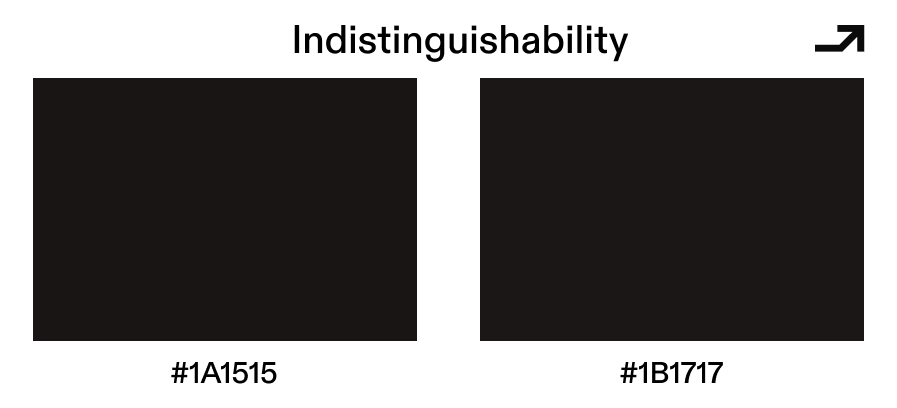
Two concepts are doing the heavy lifting in iO: obfuscation and indistinguishability. Well, no duh.
Obfuscation, in the ideal case (sometimes called virtual black-box obfuscation), means that a program that is “obfuscated” reveals nothing beyond its input-output behavior, or what goes in and what comes out. The function is effectively a black box.
Ideal Obfuscation turned out to be provably impossible for general programs. So the field settled on a weaker but still powerful guarantee: indistinguishability. The idea is that if two programs compute the same function, their obfuscated versions should be computationally indistinguishable from each other. You might, with enough effort, be able to extract more from an obfuscated program than just its outputs (so it's not a perfect black box). But the box is opaque enough that you wouldn’t be able to tell which of two equivalent implementations produced the obfuscation you're looking at.
FHE lets us run functions on encrypted data, but iO focuses on encrypting programs themselves. From an adversary's perspective, an ideally obfuscated program reveals nothing beyond its input-output behavior. No algorithm, no intermediate state, no implementation-specific structure. Run as many counterfactual statements as you want; the underlying logic, much like a hash function, can't be learned or reverse-engineered from input-output pairs.
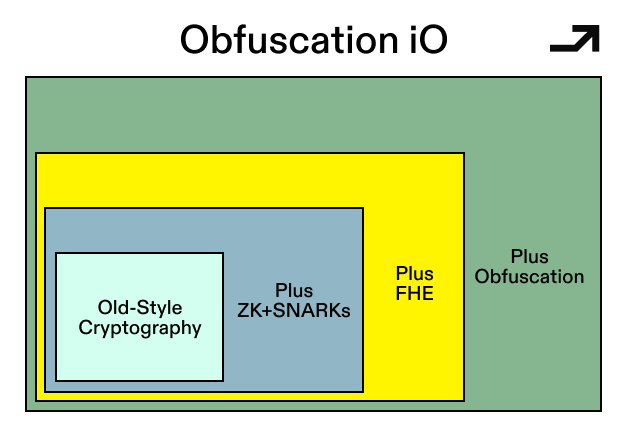
The most concrete path to iO today starts from functional encryption and builds upward through a stack of transformations. Functional encryption gives you the ability to hand out keys that each unlock a specific computation over encrypted data. From there, a series of well-defined (if expensive) transformations compose functional encryption schemes into something that can obfuscate arbitrary programs.
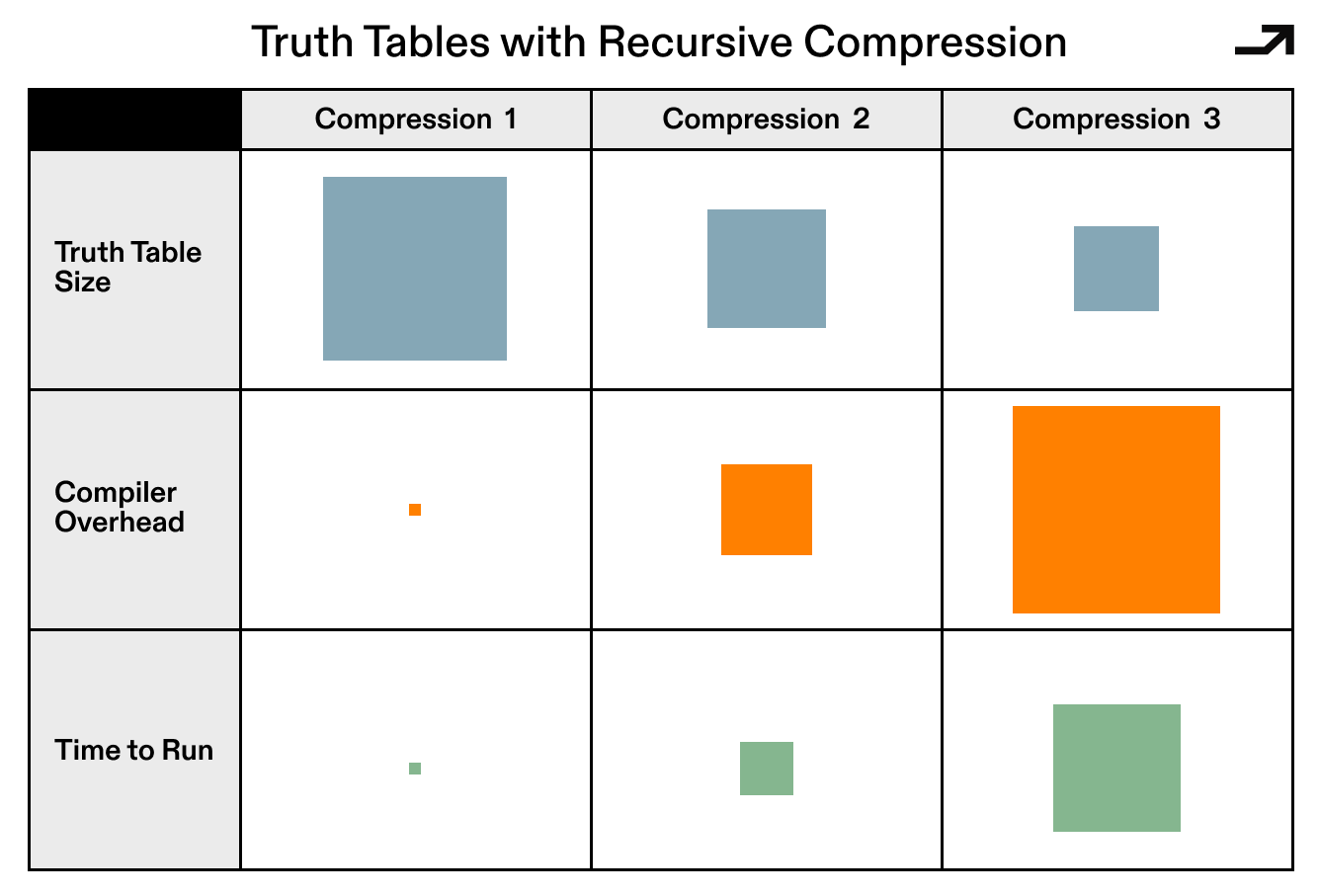
The current state of the art begins with Exponential iO, which starts from a truth table—a lookup of every logical possibility at each step of a function—sized at 2 to the power of the function's length. That sounds wildly impractical, and it is, at first. But non-trivial compression techniques can shrink these truth tables into something sub-exponential, and recursive composition of those compression steps can (in theory) collapse the whole thing down to polynomial-size circuit obfuscation. Each layer of recursion multiplies compiler overhead, and the resulting constants are still astronomical, but the mathematical scaffolding holds.
The solution here is to compress a truth table into something smaller, then repeatedly apply the same compression recursively until general polynomial-size circuit obfuscation falls out. The critical blocker is that each compression step multiplies compiler overhead, and the resulting constants are still astronomical even after many rounds of compression. As such, there’s a real desire to find something better using a new construction with fresh assumptions.
Soundness has been the primary limiting factor in implementing iO from theory into practice over the years. Since Diffie and Hellman sketched "one-way compilers" in 1976 and Barak et al proposed an indistinguishability obfuscator in 2001, every attempt to concretely construct and implement iO in an efficient and practical manner has been broken. Starting from the first concrete candidate scheme in 2013, we’ve had the same cycle cryptographers propose a new scheme, find a new assumption to support it, and watch the assumption break.
Early schemes relied on multilinear maps whose security properties turned out to be more fragile than expected. The output stage posed its own issues: because it follows a weak decryption step and produces unencrypted results, it can leak structural information about a program's internals that an adversary can use to work backwards. The 2020 and 2021 breakthrough by Jain, Lin, and Sahai collectively fixed the first of those problems for the first time in theory. The new foundation is a small portfolio of well-studied assumptions: Learning Parity with Noise (LPN), pseudorandom generators computable in NC⁰ (constant-depth circuits), and the Decision Linear assumption on bilinear pairings. Notably, LPN bears some resemblance to the learning with errors (LWE) problem that modern FHE is built around.
iO is, in theory, the most powerful single primitive in cryptography: a hub from which most of the toolkit derives, and a mathematical substitute for hardware-based trusted execution environments. The 2021 construction gave it a well-founded footing it never had before.
But…the constants are astronomical, no full implementation has been attempted, and practical deployment probably needs 2-3 major efficiency breakthroughs that don't yet have clear paths. Put another way, per Prof Lin from the University of Washington (the Lin in Jain, Lin, Sahai), iO today is where zero-knowledge proofs were in the early 2000s, before R1CS, before SNARKs, before any of the efficiency work that made deployment possible.
An iO-based Universal Cryptographic Protocol would be conditionally viable once:
iO will probably not be the first deployed UCP, nor will it realize the universality its theoretical power implies. But at the point where many other cryptographic tools could be constructed downstream of iO, ignore iO in the long term at your own peril.
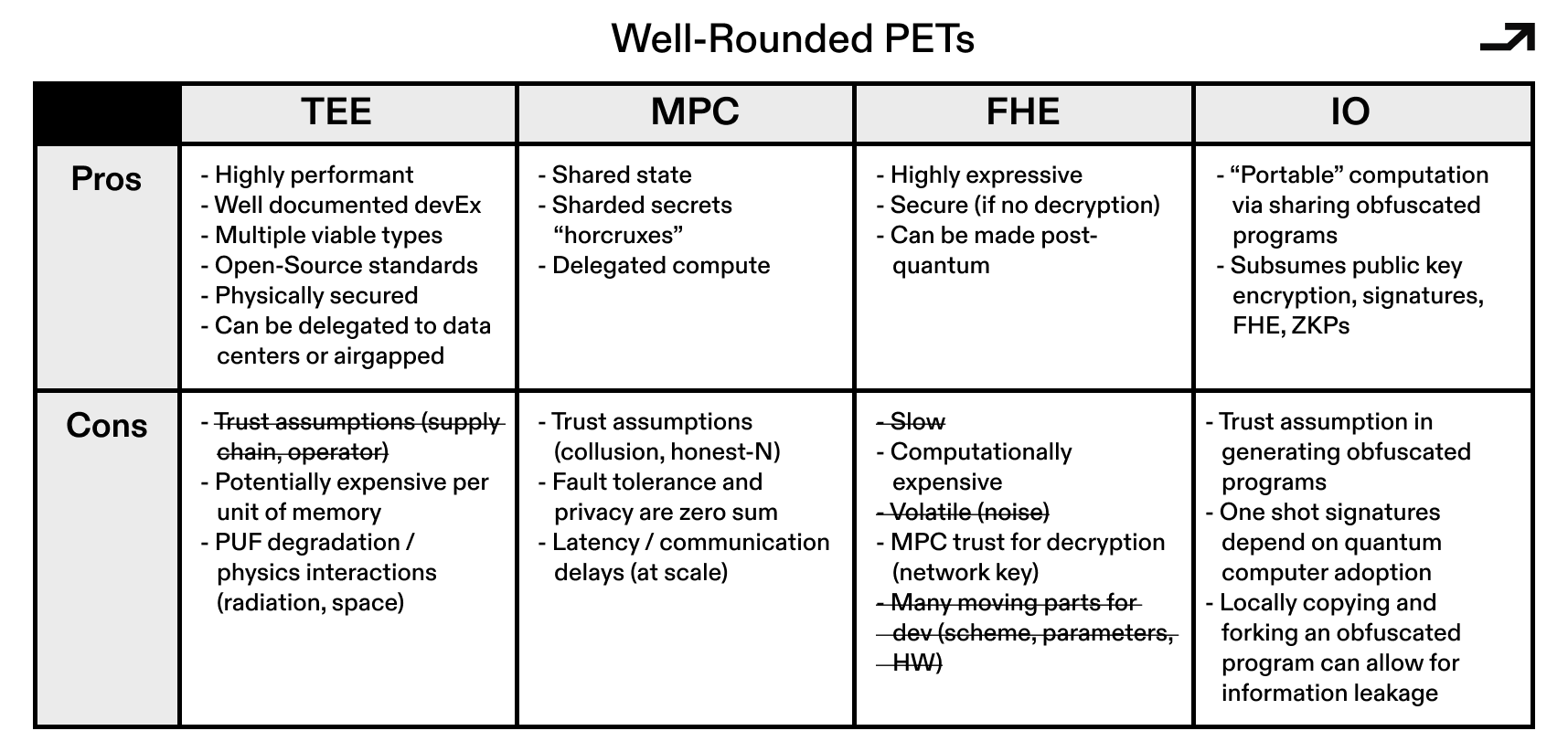
As each PET evolves, their pros and cons start to overlap. Well-rounded TEEs pick up distributed trust properties that used to be MPC's domain. FHE gets cheaper and more expressive. MPC gets faster. The structural advantages and limitations persist to an extent (communication overhead for MPC, implementation risk for open-source TEEs, computational cost for FHE), but the second order effects of these structural differences round out and the gaps between them narrow, making it possible for blockchain transactions to be private by default using a standardized privacy protocol.
Here's the thing: in the longer term, you don't actually need to care which of these routes becomes universal, unless you're investing in them. If a base-layer protocol is truly universal and good enough, it'll work roughly the same regardless of whether it's MPC, FHE, TEEs, or iO under the hood.
It’s something like DNS. What DNS server or protocol did you use on your way to this page? You don't know? I don't either, and neither do most web devs, assuming they (or you) know what DNS even is. That level of abstraction, where end users don't think about trust assumptions and developers get roughly the same experience regardless of what's underneath, is where PETs seem to be heading towards.
Privacy used to be mostly unusable, and not particularly useful for most people anyway, while regulations were out of touch with the technology. All three of those things are changing. The core PETs are getting faster and cheaper. Regulations are getting more specific and enforceable. And the use cases, from verifiable and decentralized AI to institutional onchain activity to private shared state in health, social, and advertising, are getting more concrete.
All this is to say, if you’re building in either the PET space, working on downstream use cases of privacy that change how people interact with technology, putting the “applied” in applied cryptography, or think that all of this is off-base and have an interesting reason as to why, please reach out.
Many thanks to Ravital Solomon, Andrew Miller, Prof. David Wu, the Archetype team, and others for conversing and looking over various drafts, figures, analogies, and previous bits of writing.
—
Disclaimer:
This post is for general information purposes only. It does not constitute investment advice or a recommendation or solicitation to buy or sell any investment and should not be used in the evaluation of the merits of making any investment decision. It should not be relied upon for accounting, legal or tax advice or investment recommendations. You should consult your own advisers as to legal, business, tax, and other related matters concerning any investment or legal matters. Certain information contained in here has been obtained from third-party sources, including from portfolio companies of funds managed by Archetype. This post reflects the current opinions of the authors and is not made on behalf of Archetype or its affiliates and does not necessarily reflect the opinions of Archetype, its affiliates or individuals associated with Archetype. The opinions reflected herein are subject to change without being updated.
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur.
Block quote
Ordered list
Unordered list
Bold text
Emphasis
Superscript
Subscript
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur.
Block quote
Ordered list
Unordered list
Bold text
Emphasis
Superscript
Subscript



